Podcast: Building Trust in Medical AI — Inside Med-ICE
In the latest episode of AI on the Hill in the Spotlight, host Vivian sits down with Zhiyuan Chen, a computer science graduate from Cambridge who works on large language model research at Hill Research. The conversation explores Med-ICE, a multi-agent framework designed to make medical AI more trustworthy and reliable.
Why Medical AI Needs a Different Approach
Large language models can produce fluent, confident answers that are subtly wrong. In most domains, that’s a nuisance. In medicine, it can have real consequences. Zhiyuan’s research started from a simple observation: the gap between a model’s fluency and its actual reliability is where risk lives.
“People just trust AI for no reason,” he notes. “That’s the issue.”
How Med-ICE Works
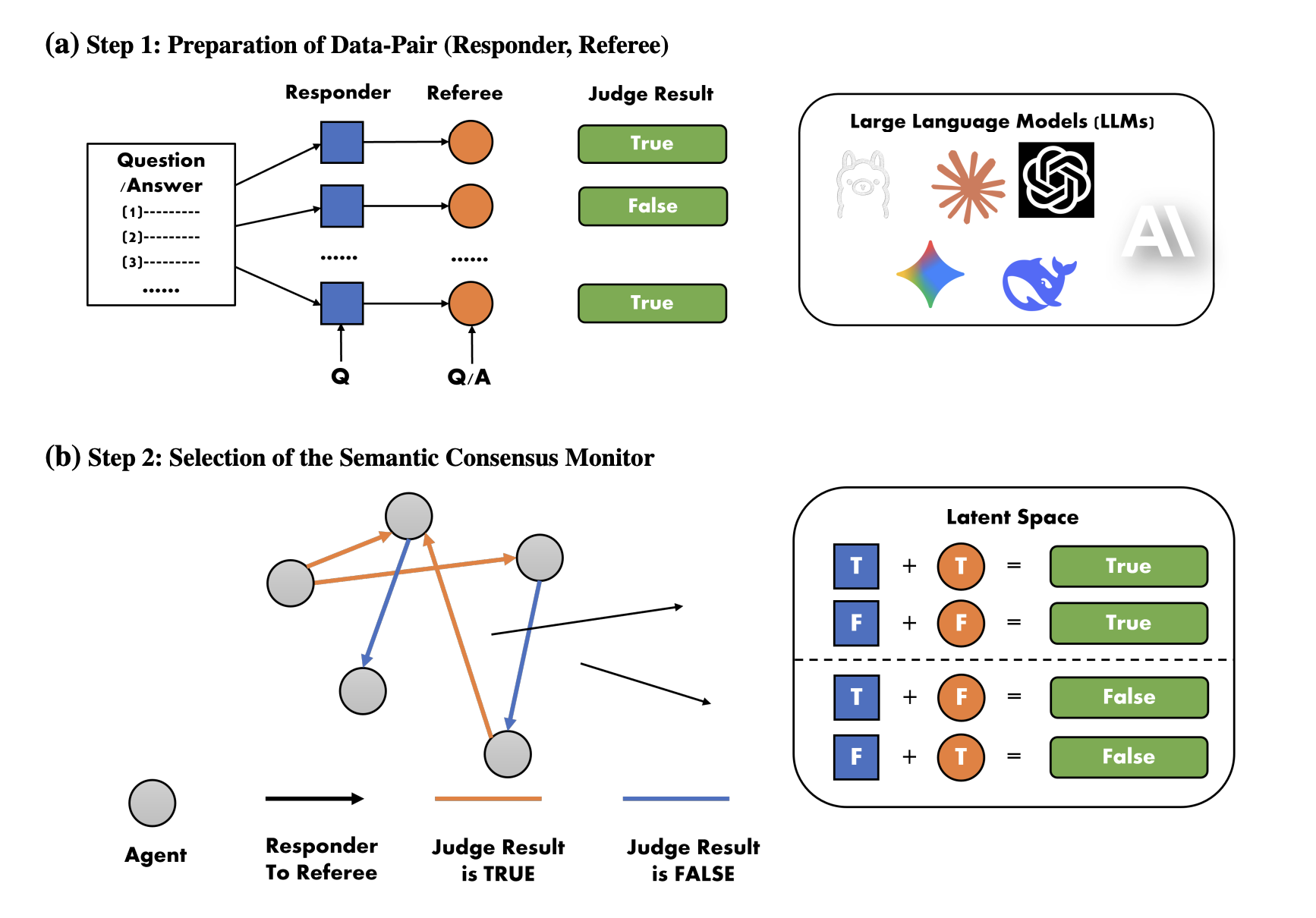
Med-ICE is a multi-agent LLM framework built for high-stakes medical tasks such as diagnosis and treatment recommendation. Instead of relying on a single model’s output, the system works in three stages:
- Multiple agents generate diverse reasoning chains — not just final answers, but structured representations including candidate diagnoses, supporting evidence, and causal relationships.
- A semantic consensus module aligns reasoning patterns — rather than simply voting on answers, the system evaluates whether the agents’ underlying medical logic converges.
- Iterative refinement — if consensus isn’t reached, all outputs are fed back to the agents for the next round, where they challenge and refine each other’s reasoning. This continues until consensus is achieved or a maximum number of iterations is reached.
The analogy is straightforward: in hospitals, difficult cases are discussed by multiple specialists. They don’t just vote — they debate, challenge each other, and converge on reasoning. Med-ICE works the same way.
Why Semantic Agreement Over Exact Matching
In clinical practice, different physicians may use different terminology to describe the same diagnosis. Exact word matching would miss these cases. Med-ICE evaluates whether reasoning paths converge semantically, not whether outputs use identical words — a distinction that matters in healthcare where multiple valid phrasings exist for the same clinical finding.
Results and What They Mean
The framework showed 5-8% improvements in factual accuracy across benchmarks. While that may sound modest, in clinical practice even small reductions in unsafe recommendations or misinterpretations can meaningfully improve risk profiles.
More importantly, the team observed fewer unsupported claims and more consistent reasoning across agents — behavioral improvements that matter beyond raw accuracy numbers.
Transparency, Not Certainty
A key design principle: Med-ICE surfaces uncertainty rather than hiding it. When agents disagree, the system makes that disagreement visible to clinicians rather than forcing a false consensus.
“Trust doesn’t come from a system claiming to be accurate,” Zhiyuan explains. “It comes from a transparent process. Clinicians can see the initial reasoning, how agents debated, and how they reached agreement.”
The system is designed as a decision-support tool — a structured second opinion that offers clinical insight without overwriting specialist judgment.
Learn More
AI on the Hill in the Spotlight is a biweekly series exploring the people and research behind Hill Research’s work in clinical AI.